
How to Evaluate and Improve Your Search Engine
Improving your search engine is a process that combines automatic optimization with strategic data management.
In this guide, you’ll learn how to enhance SupSearch’s performance through:
- Retraining
- Labelling
- Importing real-world data
- Analyzing search topics
- Identifying knowledge gaps
- Reusing labelled data across multiple search engines
All of these practices work together to deliver faster, more accurate results for your users.
Retraining and Tuning Search Engines
Once your search engine is running, SupSearch will automatically optimize itself if “Train Automatically” is enabled.
The engine retrains regularly, comparing models using a held-out dataset and staging the best-performing one. Labelled data (explained below) powers this process.
Labelling
Users with access to SupSearch can label the data under the "Training" menu of the search engine. Access to the training page requires SupSearch access level "Trainer" or higher.
Queries labelled here will always be added to the training data. By default, the queries are sorted by the score of the top predicted article. This means the queries where the search engine is most uncertain will appear at the top—making the best use of the labeller’s time.
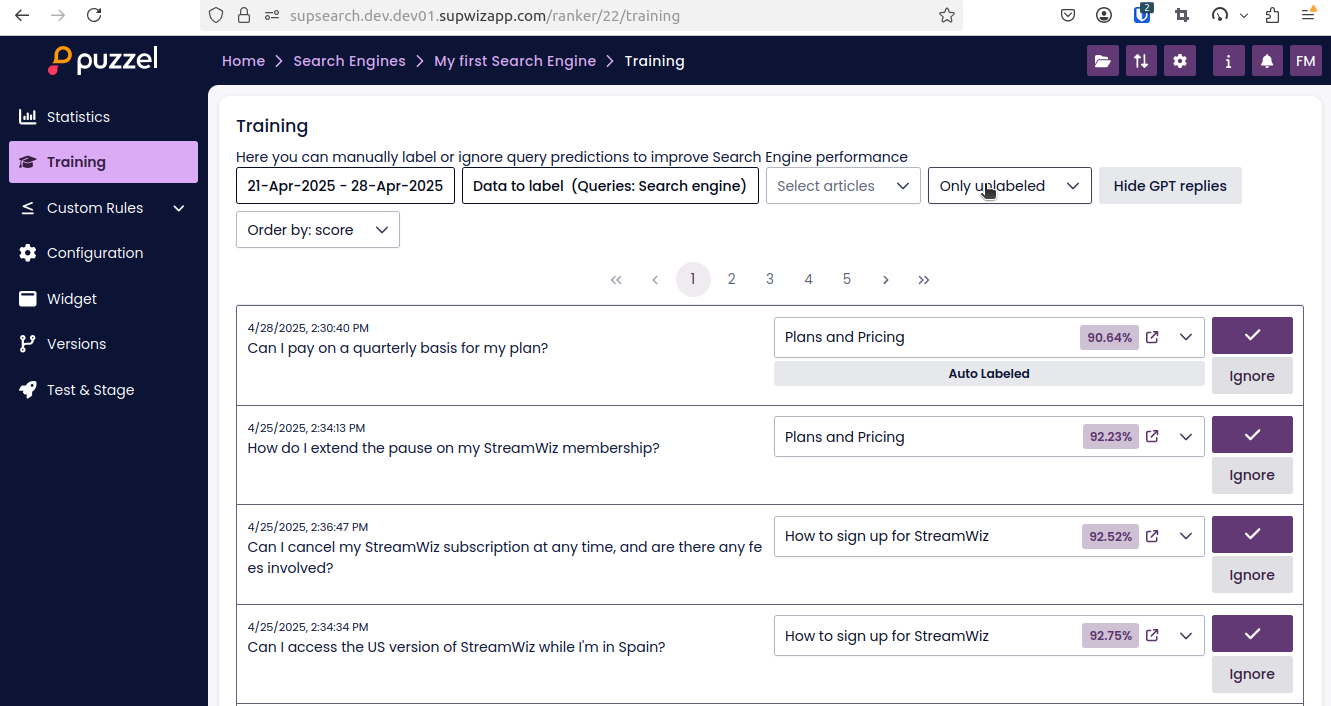
Additionally, when end users click the links in the search results, SupSearch will store that information as an auto label on the query. You can choose to include this auto-labelled data by enabling the setting on the configuration page. It is enabled by default. If you have auto labelling enabled, it’s a good idea to review end-user behaviour during the first few weeks after launch. This can help you understand how reliable the auto labels are. If user behaviour appears inconsistent, turning off auto labelling may improve search engine performance.
Data Quality
The quality of the data you provide is one of the most important factors in how well your SupSearch engine performs.
SupSearch offers powerful capabilities by default—but enhancing it with real-world data can make it even more effective.
What SupSearch Does Automatically
Out of the box, SupSearch is designed to perform well using your article content alone. Here’s what it does:
- Vector-based search indexing
Uses AI to understand the meaning behind user queries, not just the words used. Great for matching similar concepts. - Keyword-based indexing
Matches exact words or phrases from the user query to your article content. Useful for precision. - Synthetic question generation
SupSearch uses Generative AI to automatically create example questions based on your articles. These synthetic queries help the system learn how users might ask for the information.
Why Real Data Improves Performance
While synthetic questions are helpful, they may not fully match how users actually speak or type. Real users:
- Ask questions in unexpected ways
- Use slang, typos, or product-specific language
- May describe problems differently than how they're documented
If you have historic chat data—especially where agents respond with links to knowledge base articles—you already have valuable, real examples of:
- Actual user phrasing
- Which articles helped solve their problems
Feeding this data into SupSearch gives it the context it needs to better match future queries to the right answers.
Recommendation
Start with your articles and synthetic data—but don’t stop there.
If you have historical chat transcripts, use them to tune the engine further. It requires no extra effort beyond uploading the data and linking it to your search engine.
The result: smarter, faster, and more natural search experiences for your users.
Importing Historic Chat Data
From Supported Systems
For platforms like Puzzel Chat, SupChat, or Zendesk Chat:
- Create a new data source
- Select your chat system
- Provide credentials
- Import the chats
- Add the data source to your search engine
Chat data will be used the next time the engine is trained (manual or automatic).
From Other Chat Systems
If you have historic chats from a system not listed under SupSearch’s supported integrations, you can still upload the chat data manually using the Upload method.
Steps:
- Create a new Data Source
- For the Type, select "Upload"
- Once created, go to the "Chats" section using the left-hand side menu
- Click the "Upload Chats" button
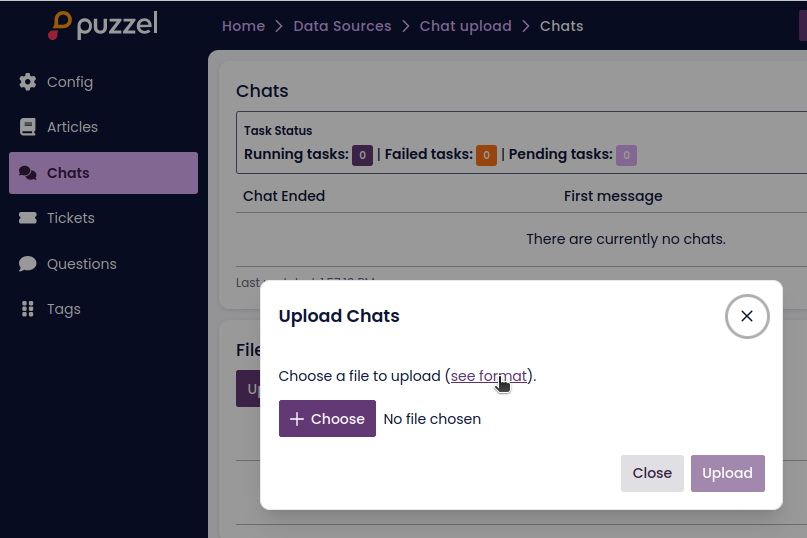
On the upload screen, you'll be able to:
- Select files to upload
- View guidance on the expected file format for chat data
SupSearch will use these uploaded conversations as additional training data to improve the search engine’s ability to understand user intent and retrieve relevant articles.
This is especially useful if:
- You’ve migrated from another platform
- You want to repurpose past support interactions for better search tuning
Statistics and Topic Analysis
The Statistics page provides valuable insight into what topics users are actively searching for. This helps you understand user intent and uncover opportunities to improve your search engine and content.
Top Topics
Under the Top Topics section, SupSearch analyzes incoming queries to detect key topics and presents a visual distribution of how often each topic appears.
Note: Key topic analysis requires that the search engine has "Improved Analytics" enabled.
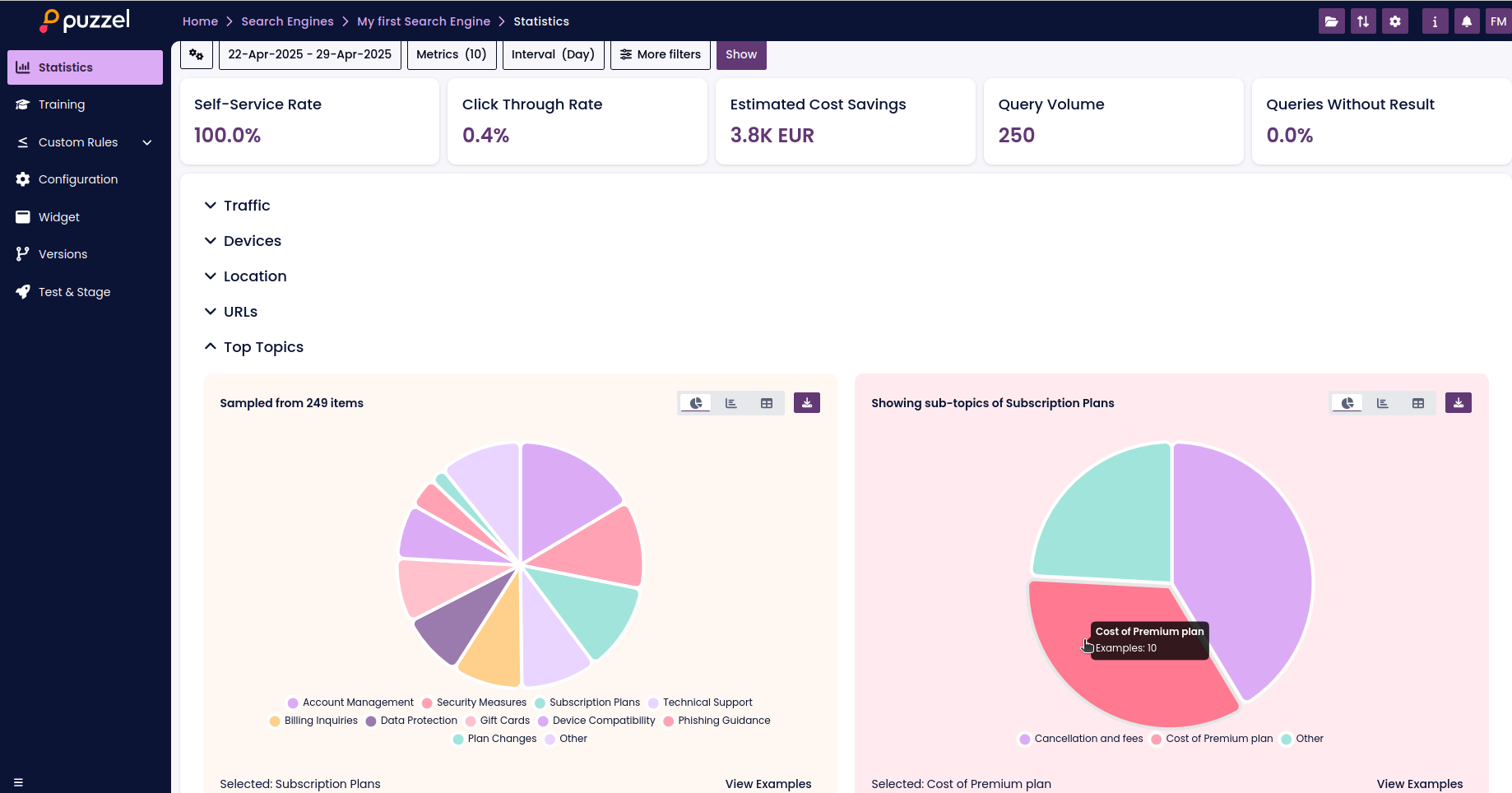
When you click on a key topic, you’ll get a further breakdown of subtopics within that category. This allows you to explore trends and patterns in more detail.
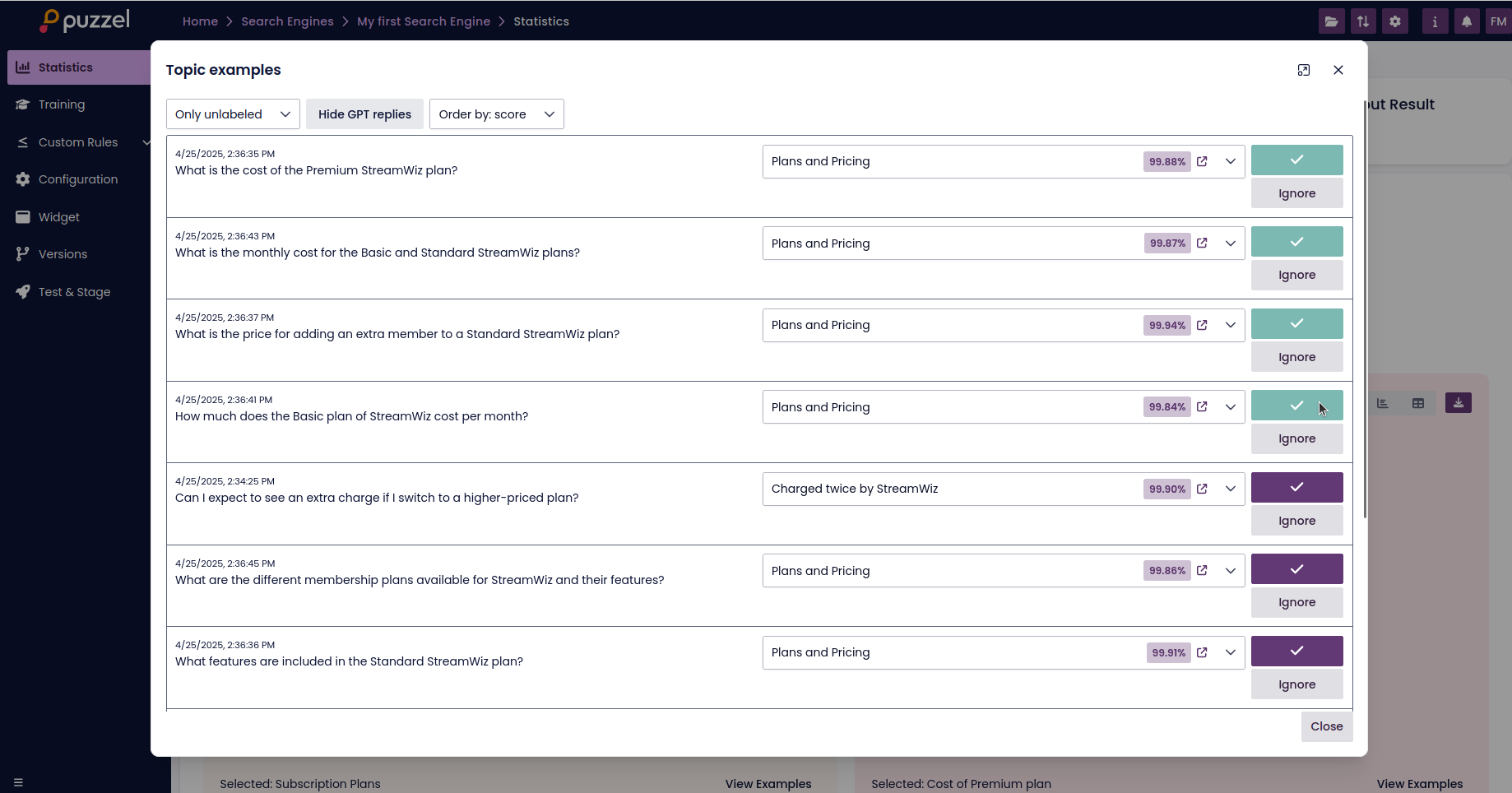
Within each key topic and subtopic, you can click the "Examples" button to view sample user queries from that category.
This feature is useful for:
- Understanding the language users use to ask about specific topics
- Finding misclassified or unlabelled queries
- Improving the labelling process by targeting specific content areas
Knowledge Gaps
The Knowledge Gap analysis is available on the Statistics page. It works similarly to the Top Topics view but with one important difference:
- It excludes queries that the search engine either:
- Was confident enough to solve
- Or have already been labelled
What’s left are the queries that the search engine is less performant on, or that fall outside the existing knowledge base.
This view is especially useful because it helps you:
- Focus labelling efforts where they matter most
- Detect missing topics or areas of user interest that aren’t yet covered in your knowledge base
The benefit is twofold:
- You improve the engine’s performance by labelling queries it struggles with.
- You identify and prioritize gaps in your content strategy.
Reusing Labelled Data
If you manage multiple search engines that rely on the same or overlapping content, SupSearch allows you to reuse labelled queries across engines. This prevents duplication of effort and accelerates training.
Example Scenario
Let’s say your organization has:
- A public article source (e.g. website)
- An internal article source (e.g. intranet)
- A search engine for external users (using public articles only)
- A search engine for internal users (using both public and internal articles)
In this case, you can reuse the labelled query data from the external search engine in the internal one, since both reference the public articles.
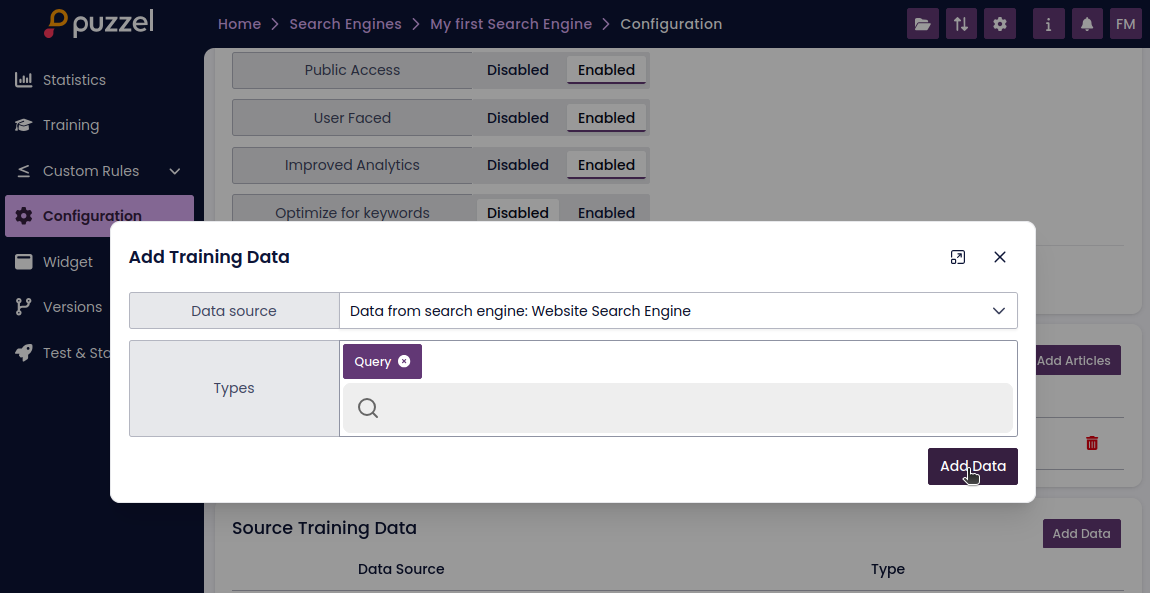
How to Reuse Labelled Data
- Go to the configuration page of the internal search engine
- Under the "Source Training Data" section, click "Add Data"
- Choose the external search engine as the source
- Select data type: Query
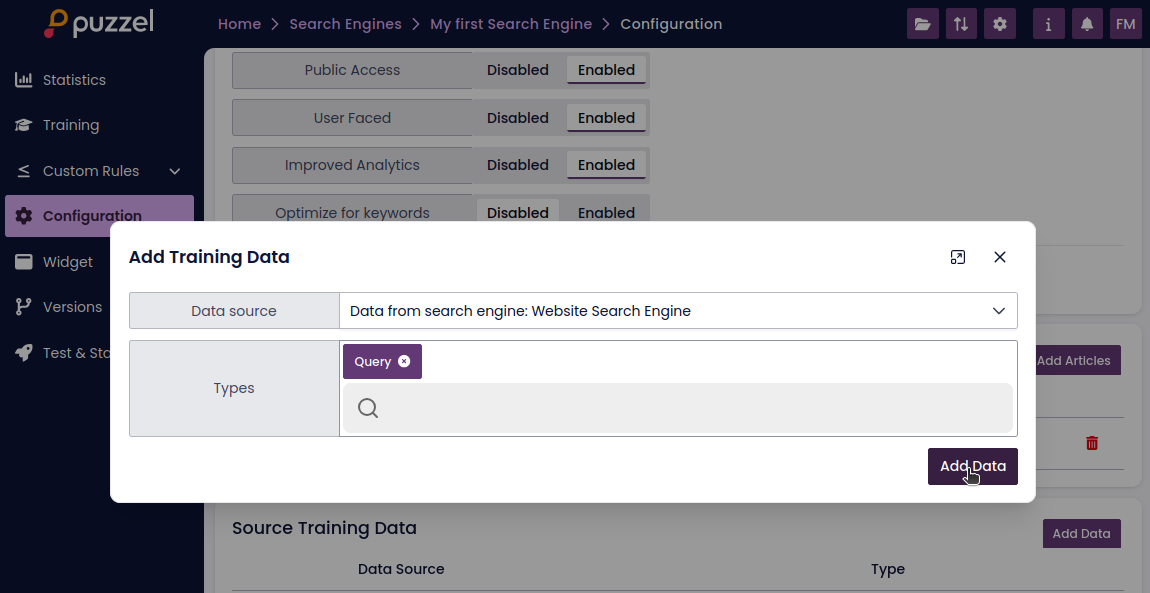
Note: Only queries referencing articles available in both search engines will be included.
This feature allows you to bootstrap internal engines with existing training data, reducing time-to-value and improving consistency across user experiences.